WHAT |
A moduler and extensible simulation framework for MapReduce |
WHEN |
August 2012-May 2013 |
WHO |
Me, Trony O'Neil, and Matthew O'Shaughnessy; advised by Xiao Yu of the Parallel and Distributed Computing Lab |
WHERE |
Georgia Tech, Opportunity Research Scholars (ORS) |
WHY |
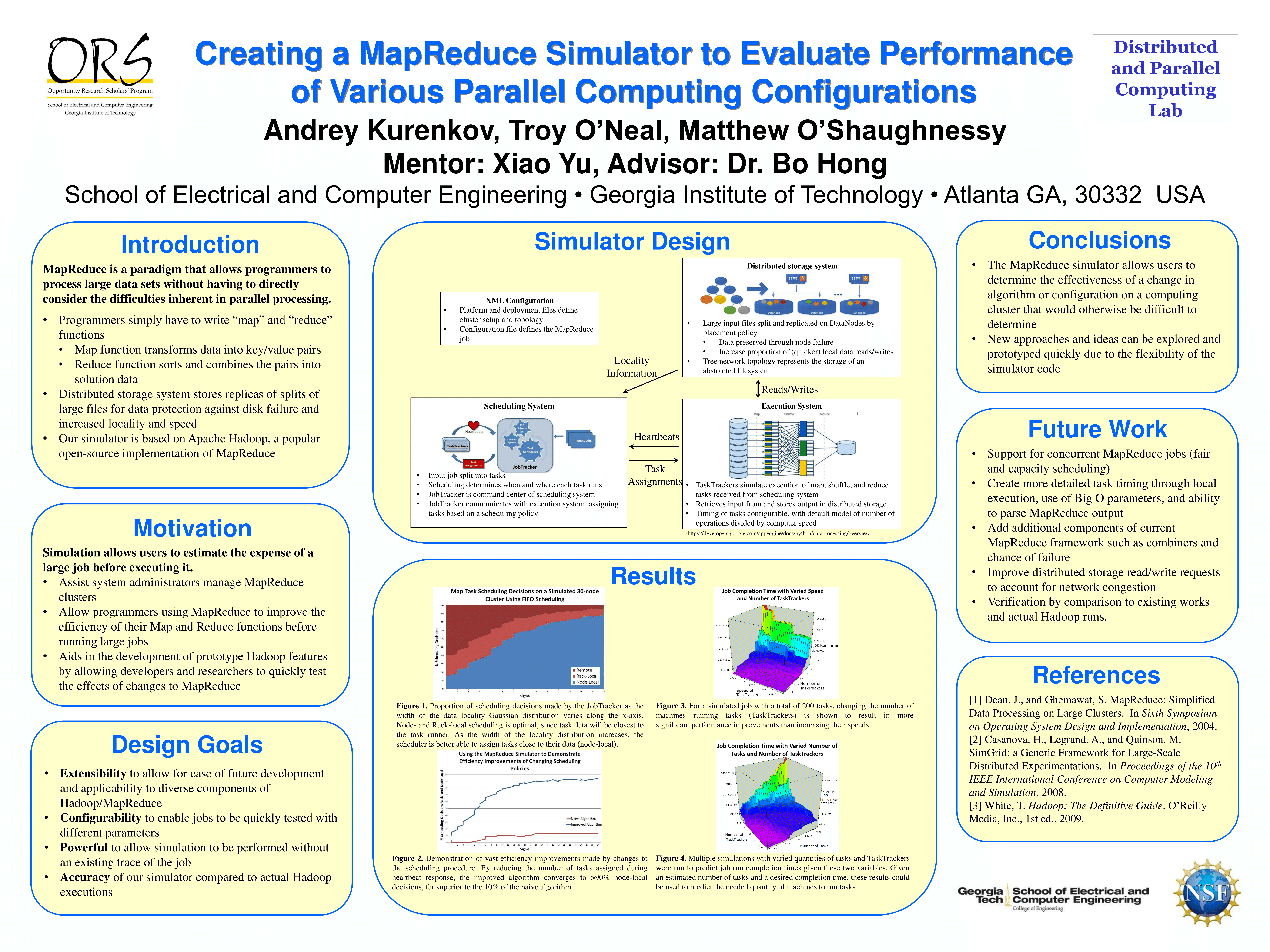
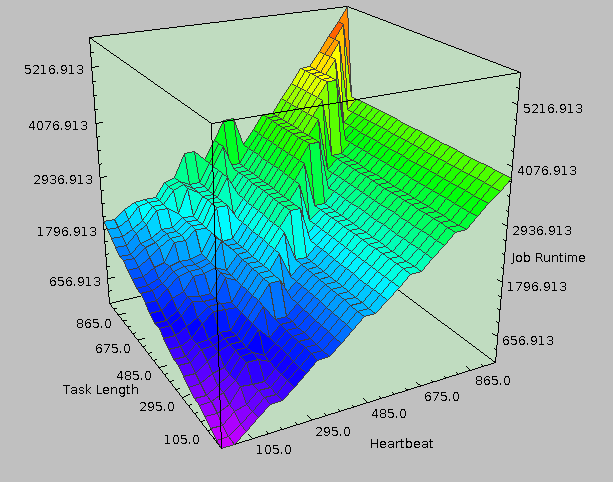
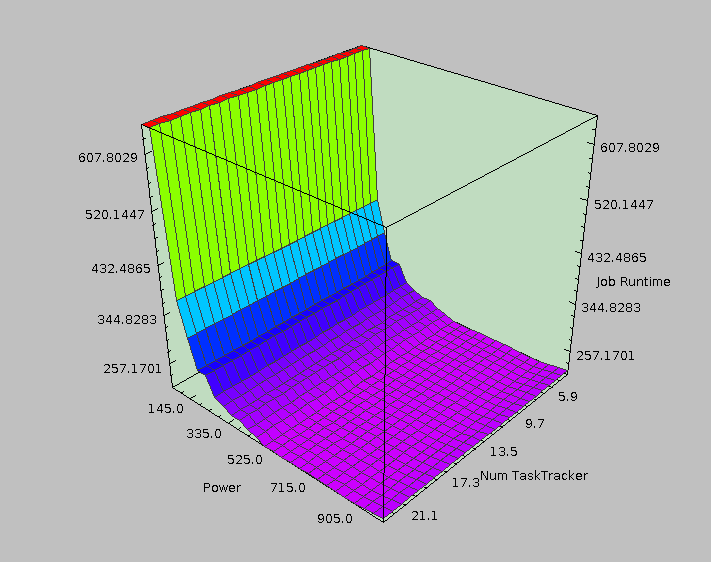
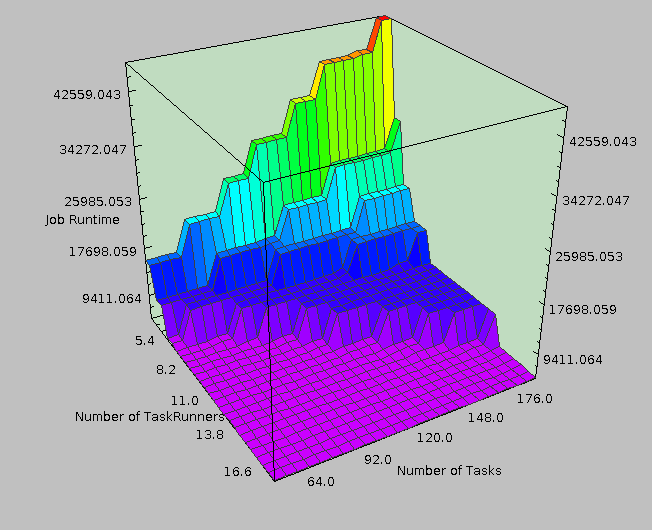
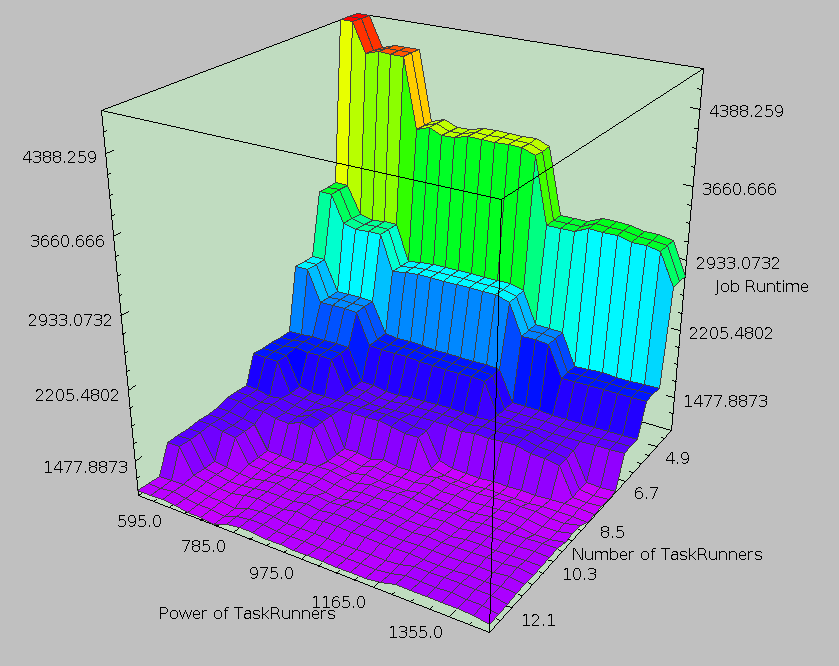
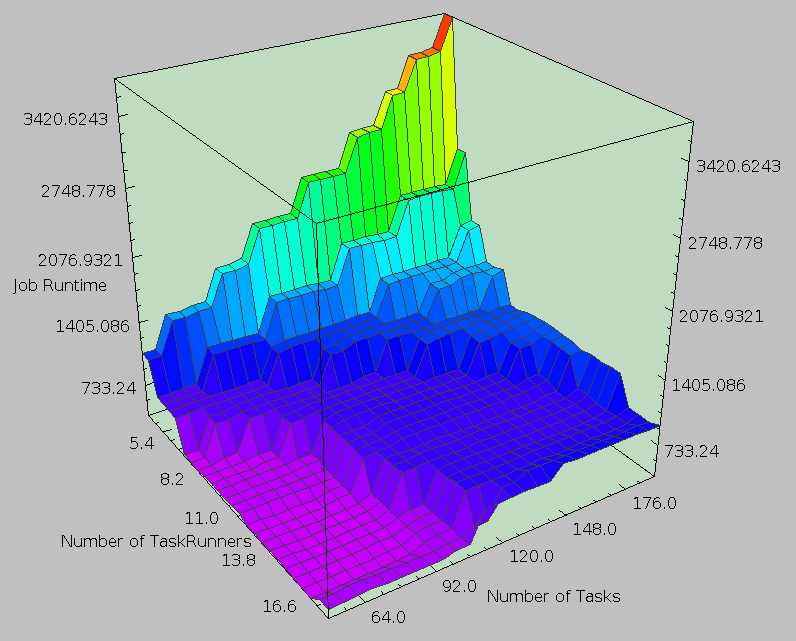
MapReduce is huge, and configuration is complicated. |
HOW |
How indeed. Implementing an efficient single-core program to estimate large scale data processing with enough detail to actually produce useful results is a challenging problem. Not only that, but we soon found similar things existed: + SimMR: Univ. of Illinois Urbana-Champaign; HP Labs Narrowly focused on scheduler selection and Map/Reduce slot allocation + Rumen/Mumak: Hadoop Powered by a previous job trace Narrowly focused on scheduler selection + MRSim: Brunel University Many hardcoded properties (limited extensibility) + MRPerf: Virginia Tech; IBM Flexibility limited to certain configurable items Ultimately, we implemented an impressively modular and extensible simulation engine but failed to built in much of the detail required to make it useful. Still, despite not doing anything impressive (in my view), we got the second place for best poster among those presenting and ended up with some nice looking results. |
LINKS |
|
PICS |