WHAT |
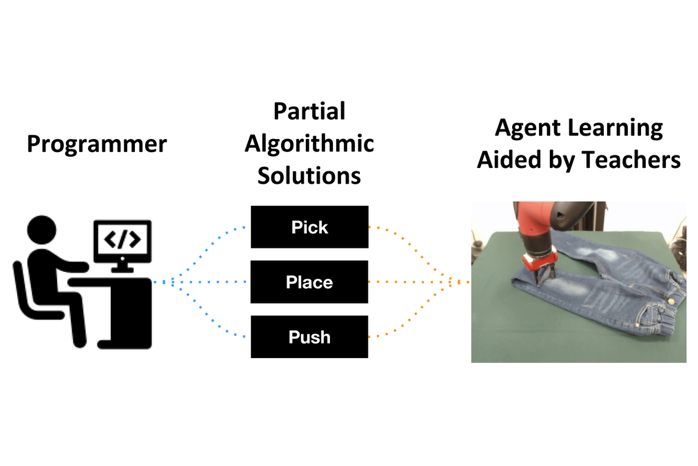
A unifying approach to leverage advice from an ensemble of sub-optimal teachers in order to accelerate the learning process of actor-critic reinforcement learning agents. |
WHEN |
November 2018 - July 2019 |
WHO |
Andrey Kurenkov, Ajay Mandlekar, Roberto Martin-Martin, Silvio Savarese, Animesh Garg |
WHERE |
Stanford Vision Lab |
WHY |
RL is too slow for robotics |
HOW |
|
LINKS |